
Introduction
The recent surge in the availability of online videos has changed the way of acquiring information and knowledge. Many people prefer instructional videos to teach or learn how to accomplish a particular task in an effective and efficient manner with a series of step-by-step procedures. Similarly, medical instructional videos are more suitable and beneficial for delivering key information through visual and verbal communication to consumers' healthcare questions that demand instruction. We aim to extract the visual information from the video corpus for consumers' first aid, medical emergency, and medical educational questions. Extracting the relevant information from the video corpus requires relevant video retrieval, moment localization, video summarization, and captioning skills. Toward this, the TREC task, Medical Video Question Answering, focuses on developing systems capable of understanding medical videos and providing visual answers (from single and multiple videos) and instructional step captions to answer natural language questions. Emphasizing the importance of multimodal capabilities, the task requires systems to generate instructional questions and captions based on medical video content. Following the MedVidQA 2023, TREC 2024 expanded the tasks considering language-video understanding and generation. This track is comprised of two main tasks: Video Corpus Visual Answer Localization (VCVAL) and Query-Focused Instructional Step Captioning (QFISC).
News
- September 2, 2024: Test Set for Task B released.
- June 7, 2024: Test Set for Task A released.
- May 12, 2024: Video corpus released.
- April 30, 2024: Training and Validation datasets released.
- February 12, 2024: Introducing the MedVidQA 2024 challenge.
Important Dates
| Video Corpus Release |
Training/Val Set Release |
Test Set Release |
Submission Deadline |
Official Results |
|
|---|---|---|---|---|---|
| Task A | May 12 | April 30 | June 7 | August 2 | September 8 |
| Task B | NA | April 30 | September 2 | September 16 | October 11 |
Registration and Submission
- Participants are required to complete their registration by submitting the TREC 2024 Registration Form. Registered teams will be added to TREC 2024's mailing list for future communication.
- Submissions: Participants are required to submit the runs via the Evalbase platform provided by NIST. Please see the registered email for more details.
Tasks
-
Task A: Video Corpus Visual Answer Localization (VCVAL)
Given a medical query and a collection of videos, the task aims to retrieve the appropriate video from the video collection and then locate the temporal segments (start and end timestamps) in the video where the answer to the medical query is being shown, or the explanation is illustrated in the video.
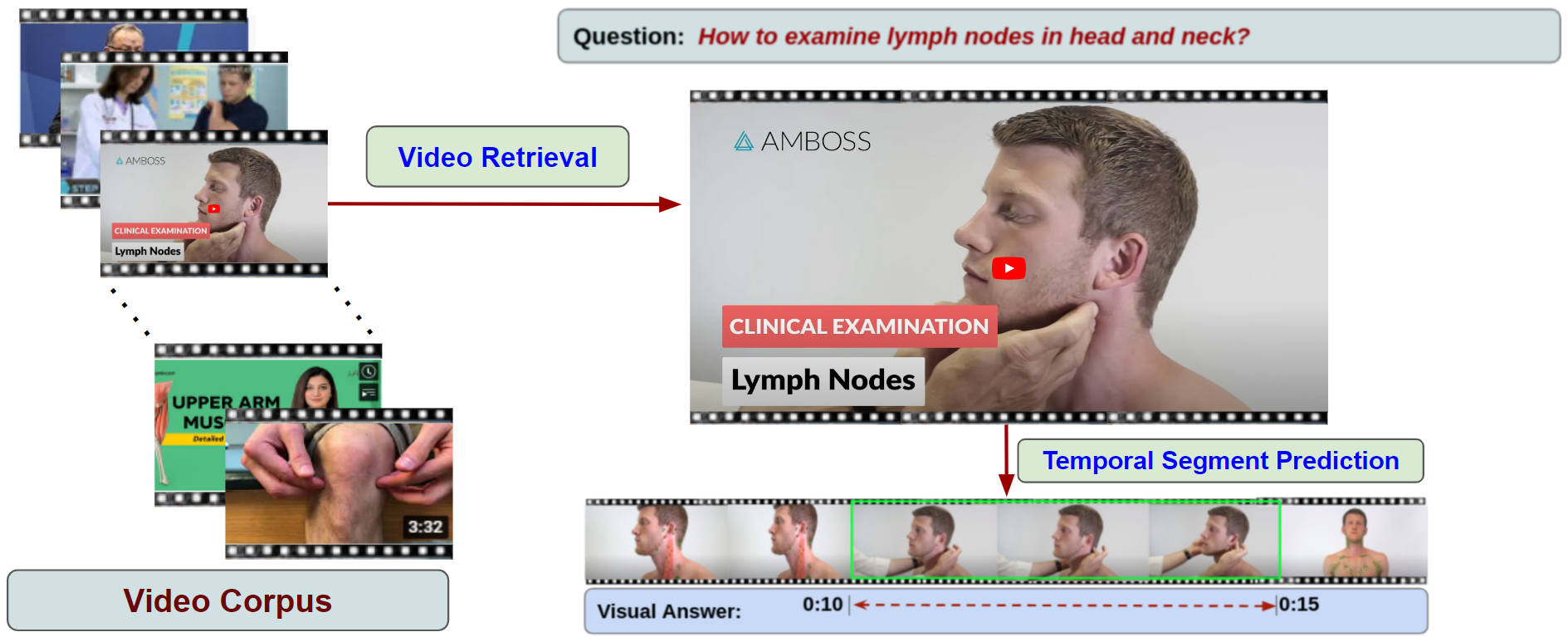
Schematic workflow of the video corpus visual answer localization task. -
Task B: Query-Focused Instructional Step Captioning (QFISC)
Given a medical query and a video, this task aims to generate step-by-step textual summaries of the visual instructional segment that can be considered as the answer to the medical query. The proposed QFISC task can be considered an extension of the visual answer localization task, where the system needs to locate a series of instructional segments that serve as the answer to the query. The QFISC demands identifying the instructional step boundaries and generating a step caption for every step. This task comes under multimodal generation, where the system has to consider the video (visual) and subtitle (language) modality to generate the natural language caption.
Datasets
-
Task A
-
Training and Validation Datasets:
MedVidQA collections [1] consisting of 3,010 human-annotated instructional questions and visual answers from 900 health-related videos.
Download Datasets
-
Training and Validation Datasets:
MedVidQA collections [1] consisting of 3,010 human-annotated instructional questions and visual answers from 900 health-related videos.
-
Task B
-
Training and Validation Datasets:
Open domain HIREST dataset [3] to train the system
for Task B. HIREST comprises 3.4K text-video pairs sourced from an instructional video
dataset. Among these, 1.1K videos are annotated with moment spans pertinent to text
queries. Each moment is further dissected into key instructional steps, complete with captions
and timestamps, resulting in a total of 8.6K step captions.
Download Datasets
-
Training and Validation Datasets:
Open domain HIREST dataset [3] to train the system
for Task B. HIREST comprises 3.4K text-video pairs sourced from an instructional video
dataset. Among these, 1.1K videos are annotated with moment spans pertinent to text
queries. Each moment is further dissected into key instructional steps, complete with captions
and timestamps, resulting in a total of 8.6K step captions.
Evaluation Metrics
-
Task A
- The VCVAL task consists of two sub-tasks: video retrieval (VR) and visual answer localization (VAL). We will evalaute the performance of the video retrieval system in terms of Mean Average Precision (MAP), Recall@k, Precision@k, and nDCG metrics with k={5, 10}. We will follow the trec_eval evaluation library to report the performance of participating systems. For the VAL task, following MedVidQA 2023, we will use Mean Intersection over Union (mIoU) and IoU =0.3, IoU=0.5 and IoU=0.7 as the evaluation metrics.
-
Task B
-
We plan to evaluate the performance of the step captioning task on two fronts: (1) how close the system-generated step caption is to the ground truth step captions, and (2) how well the predicted step segment aligns with the ground truth step segment.
- We will measure the closeness in two ways:
- With the help of predicted timestamps and sentence-level similarity (ROUGE-L) of the step, we will align a predicted step to one of the ground truth steps. Once a predicted or ground truth step is matched, it is no longer considered, so there will be only one-to-one matching. Towards this, we define the following:
- TP (True Positives): Represents the count of predicted steps that are present in the ground truth steps.
- FP (False Positives) : Represents the count of predicted steps that are not present in the ground truth steps.
- FN (False Negatives): Represents the count of ground truth steps that are not present in the predicted steps.
- We will use the n-gram matching metrics: CIDEr [4], and SPICE [5]. Additionally, we plan to use sentence-level embedding-based metrics, BERTScore [6] as it captures the semantic similarity between the generated and ground truth captions.
- To compute the alignment between the predicted step segments and the ground truth step segments, we will use the intersection over union (IoU) metric. For a given step, IoU is computed as the ratio of the common segment to the union between the predicted and ground-truth segments. It ranges from 0 to 1. For the shorter step, where the step segment lasts, say, only 1-2 seconds, if the system-generated step segment does not match with the ground-truth segment, the system may end up with IoU=0. To deal with such a situation, we will use relaxed IoU, where we will extend the segments by λ before computing the IoU. We will compute the mean of the IoU for all the segments in the test set.
- We will measure the closeness in two ways:
-
We plan to evaluate the performance of the step captioning task on two fronts: (1) how close the system-generated step caption is to the ground truth step captions, and (2) how well the predicted step segment aligns with the ground truth step segment.
Organizers
 Deepak Gupta
NLM, NIH
Deepak Gupta
NLM, NIH
 Dina Demner-Fushman
NLM, NIH
Dina Demner-Fushman
NLM, NIH